专题:DeepSeek崛起 国产AI重挫好意思股开yun体育网
一家中国大模子公司,何如别具肺肠,改造牌局?
作家 | 周可
着手 | 豹变
这个春节假期,不管你是不是科技新闻的耐久读者,冒昧率逃不外一款名为 DeepSeek的AI家具关系资讯不竭刷屏。
一切始于1月20日,中国科技公司深度求索推出推理模子DeepSeek-R1,仅用 OpenAI十分之一的成本就达到其最新模子GPT-o1同级别的发扬。
此前,深度求索告示其推出的DeepSeek-V3仅花消558万好意思元,不到外洋公司十分之一的GPU芯片和检修时长,就已毕了与GPT-4o和Claude Sonnet 3.5等花消数亿好意思元检修的顶尖模子终点的性能。这一音书速即激起大家科技界不竭见谅。
R1发布后的十天内,DeepSeek先后登上中国、好意思国等70多个国度苹果哄骗商店下载榜榜首。这是大家范围内,初度有家具超越OpenAI的ChatGPT。几年来,AI竞赛的蹙悚第一次传导到好意思国科技公司。
DeepSeek火爆之下,对算力需求是否产生负面影响的参谋,也激励了华尔街忌惮。1 月27日,好意思国主要科技股市值开盘缩水超1万亿好意思元,英伟达股价带头跳水 16.86%,市值挥发5890亿好意思元,终点于跌没了两个阿里巴巴。甲骨文着落 13.78%,超微电脑着落 12.49%,芯片制造商博通着落 17.4%,台积电跌 13%。
科技股股价暴跌的同期,好意思国科技公司动手策划、效法中国敌手。据报谈,Meta已成就四个小组专诚策划DeepSeek。同期,更多质疑和会剿也相继而至。
畴昔几年的AI竞赛中,中国互联网和科技公司耐久是好意思国公司的侍从者,中国公司只可寄但愿于用更多的资源参加追逐敌手,但风向耐久由OpenAI、Meta为代表的好意思国公司掌持。2022年起,好意思国政府告示升级芯片出口管制,而后屡次更新出口完毕清单,完毕高算力芯片出口,中国AI企业遍及堕入算力蹙悚。
DeepSeek最新模子的出现,冲破了大模子发展沦为巨头与本钱游戏的行业共鸣,为业内追逐好意思国大模子的中国公司们提供一条新的念念路:绕过好意思国堆算力的技巧旅途,优化算法、探索效力优先,走一条“低成本高产出”沿路,也不错已毕弯谈超车。
量化基金布景的大模子,
何如弯谈超车?
在本次新模子发布激励大家见谅后,一些外洋媒体和投资者一度将DeepSeek称为一家不有名的中国公司。这种描述并不准确。
DeepSeek背后的深度求索是一家创立于2023年的年青公司,但其母公司幻方量化,是解决了特出1000亿元财富的国内头部量化交往公司,在多年前就动手涉足AI 策划。
DeepSeek独创东谈主梁文锋最早开启AI策划的初志是,用GPU筹备交往仓位,检修量化交往模子。而后,出于探索AI才能领域的敬爱,他们囤积了过万块先进GPU芯片动手检修AGI模子,储备量接近国内一线互联网公司,高于大模子创业六小龙。这为DeepSeek日后的模子进展打下了基础。
DeepSeek也不是出乎预看法“惊艳”整个东谈主,在近期推出的V3和R1模子之前,它就曾以带头打响大模子价钱战而在国内AI行业激励见谅。2024年5月,DeepSeek发布DeepSeek-V2 ,价钱仅为GPT-4-Turbo的近百分之一。
而后的30天,字节、百度、阿里等公司的大模子相继降价,DeepSeek更是一年内3次降价,每次降幅特出85%。
降价,来自检修和推理成本的不竭缩短。比拟OpenAI和它的中国效仿者们用数亿好意思元检修大模子,DeepSeek遴荐了一条更“吝惜”,更“极致”的阶梯。
它的策划东谈主员冷落的一种新的MLA(一种新的多头潜在阻拦力机制)架构,与 DeepSeek MoESparse (夹杂大家结构)蚁合,把显存占用降到了其他大模子最常用的MHA架构的5%-13%。
行业经常用数万亿token(文本单元)检修模子,但DeepSeek通过“数据蒸馏”技巧,即用一个高精度的通用大模子当古道,而不是用题海战术来更高效检修学生“模子”,把数据筹备最猛进度缩短,仅用1/5的数据量达到同等效力,促成了成本的下降。
一个普通的例如可匡助咱们交融这种变化,传统大模子每次处理问题齐需激活全部参数,而普通用户冷落的问题可能并不需要如斯多的资源参加,这如同让一家病院的全部科室去诊断一个普通伤风;而DeepSeek-R1会先判断问题类型,再精确调用对应模块——数学题交给逻辑推理单元,写诗则由体裁模块处理。这种遐想让模子反应速率擢升3倍,能耗也更低。
更快速率和更粗劣耗,建设在“低成本、高性能”的运转贪图上。DeepSeek通过算法优化权贵缩短检修成本。R1 的预检修用度只好557.6万好意思元,在2048块英伟达H800 GPU(针对中国商场的低配版GPU)集群上运行55天完成。此前,OpenAI等企业检修模子,齐需要数千致使上万块高算力的Nvidia A100、H100等顶级显卡,花消数亿好意思元的检修成本。
并非 OpenAI 或者中国大公司的大模子开采者们莫得猜度过此类模块化决议的可能性,而是他们比权量力,遴荐了更符合自身发展情况的决议。
OpenAI领有资金和算力上的实足上风,优先追求“通用智能”,他们花消数十亿好意思元,通过海量参数投喂检修模子,但愿模子不错达到万能通才的效力。效仿它的中国公司们沿用这一念念路,不错保证自家大模子莫得昭彰的才能短板,快速达到可商用水平。
DeepSeek遴荐从垂直场景切入,从 all in 特定范围动手,追求在部分范围(如数学、代码)的发扬更优,再冉冉分阶段完善其他范围的才能。
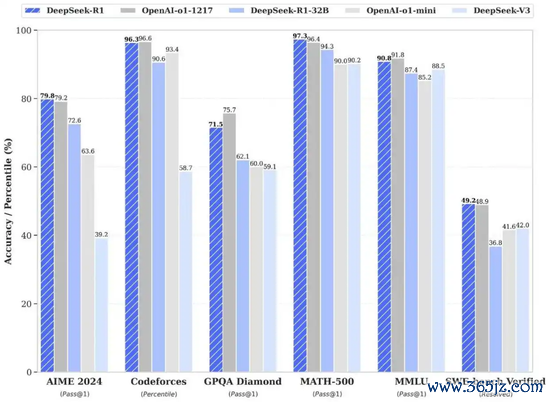
DeepSeek R1 与 OpenAI O1郑再版在数学、代码、当然谈话推理等任务下的测试收货终点。
这种别具肺肠意味着更高难度
,更高风险。若路由无理(例如将诗歌创作误判为数学题),输出质地将会暴跌;模块间的学问阻遏(如用数学公式写情书),可能导致跨范围任务失败。要是未能开采出富足优异的模块化模子,前期的参加可能破坏。大多数公司受限于旅途依赖或资源治理,难以承袭All in这一高风险阶梯。
这并辞谢易。早期DeepSeek的MoE模子误判率遍及在15%以上,团队通过引入强化学习优化路由决策,耐久检修后模子在测试中将误判率适度在个位数的低位。
多位行业东谈主士将DeepSeek的脱颖而出交融为
“模块化特种兵”
,在与OpenAI等“通用巨兽”的比赛中,在部分范围展现出同等才能致使稍微率先。尽管DeepSeek的举座技巧与OpenAI等好意思国企业存在差距,但其一经足以被视为一个实力缓缓接近的竞争敌手。
更要害的是, DeepSeek 跳过了好意思国开采者们觉得必不可少的法子,这意味着在资金、算力芯片错误的情况下,中国乃至天下各地的AI创业公司也有可能弯谈超车,无谓活在大公司的暗影之下,垂直范围的专注也能匡助他们在特定场景中造成上风,幸免与巨头正面竞争,找到属于我方的驻足之地。
开源模子,DeepSeek的遴荐与壁垒
DeepSeek引起震憾,除了模子自己的优异发扬,还来自其宝石的免费开源主张,公开模子的源代码、权重和架构。这意味着,不管是个东谈主如故开采者,或是企业用户齐不错免费使用其最新模子,并在此基础上开采更多哄骗。
这一决策得到了很多行业大家和投资者的维持。
英伟达高等策划科学家Jim Fan筹商称,“咱们生计在这么一个时期,一家非好意思国公司正在让OpenAI的初志得以延续,即作念果真绽开、为整个东谈主赋能的前沿策划。”
硅谷风投A16Z独创东谈主Marc Andreessen也发表筹商称,DeepSeek-R1 是他见过的最令东谈主惊叹且令东谈主印象长远的一个突破,动作开源的模子,它的面世给天下带来了一份礼物。
OpenAI最初是为了叛逆谷歌在AI范围的把持地位,旨在通过开源的形势促进AI技巧的发展,幸免谷歌在AI范围的过度适度,因此定名为 “OpenAI” 以体现其开源的愿景。但在GPT-3发布,承袭微软投资后,OpenAI 出于检修成本、收益和保管其竞争力的研讨走向闭源。
现在发扬强盛的其他大模子,如Meta的Llama堪称遴荐了开源阶梯,但许可证需要肯求拜谒权限,完毕部分交易用途,且只公开了部分架构细节,不公开具体的检修数据组成,不提供圆善的检修剧本。这么的开源对于AI产业的向上意思十分有限。
大多数中国大公司开采的大模子,如百度的文心一言、华为的盘古大模子等家具齐遴荐了闭源阶梯,它们经常是基于交易化和竞争考量,平台型公司有富足多的资源,掌持了多数的用户数据,不错依靠自身的里面轮回完成模子的检修和迭代。闭源不错让他们在模子专长的范围保持上风,幸免被竞争敌手赶超。
DeepSeek遴荐开源,
既是出于对传统大厂的技巧把持的挑战,亦然基于自身发展情况的考量
。创业公司可能在资源和算力上处于错误,但通过开源计谋,不错快速建设生态,
获取更多的用户和开采者复旧
。
DeepSeek独创东谈主梁文锋此前谈及对于开源的构想是,成为更多公司的模子底座。哪怕一个小 APP齐不错低成本去用上大模子,而不是技巧只掌持在一部分东谈主和公司手中,造成把持。
在他看来,DeepSeek将来不错只崇拜基础模子和前沿的革命,其他公司在 DeepSeek的基础上构建To B、To C的业务。要是能造成圆善的产业凹凸游,就没必要我方作念哄骗。
DeepSeek所遴荐的模块化模子遐想,如同精密的钟表——单个齿轮的工艺未必可复制,但举座协同需要耐久试错与生态积攒。竞争敌手并弗成依靠节略照搬就能复制其原始模子,越多的用户和开采者使用,则意味着模子得到更多检修。
当下,DeepSeek背靠千亿量化基金,在免去资金的黄雀伺蝉后,遴荐了一条颇显想象主张的旅途,即只作念模子策划,不研讨交易变现,通过开源基础模子诱骗开采者,将来再冉冉通过企业版用具链(如模块检修平台)鞭策交易化。
今天的AI竞争模式之下,对于一家创业公司,开源不仅是技妙策谋,更是参与制定行业规章的要害落子。在模子才能缓缓透明的将来,果真的竞争上风将来自构建数据反馈闭环的才能,以及将技巧影响力转机为交易生态的才能。
这履行上是
一场对于“递次制定权”的争夺
——谁的开源条约能成为行业事实递次,谁就能鄙人一代AI基础设施中占据中枢位置。中国科技公司与好意思国科技公司
之间的差距,不是时候维度,而是革命和效法的辩认。
这一次,DeepSeek 代表的中国科技公司给出的决议不再是效法侍从,而是革命。
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
包袱剪辑:韦子蓉 开yun体育网